Duże modele językowe (LLM), takie jak te napędzające popularne chatboty, stały się naszymi codziennymi doradcami. Pytamy je o wszystko: od przepisów kulinarnych, przez pomoc w pracy, po złożone kwestie medyczne i prawne. Ufamy im. Ta rosnąca zależność rodzi jednak fundamentalne pytanie: skąd wiemy, kiedy model AI jest pewny swojej odpowiedzi, a kiedy jedynie „zgaduje”, prezentując informację w przekonujący sposób? Błąd w przepisie na ciasto jest drobnostką. Błąd w poradzie dotyczącej zdrowia może mieć poważne konsekwencje. Nowe, wnikliwe badanie rzuca światło na niebezpieczny rozdźwięk między tym, co modele językowe faktycznie „wiedzą”, a tym, co my, jako użytkownicy, myślimy, że wiedzą.
Rozdźwięk, którego nie widać: dlaczego ufamy maszynie bardziej niż powinniśmy?
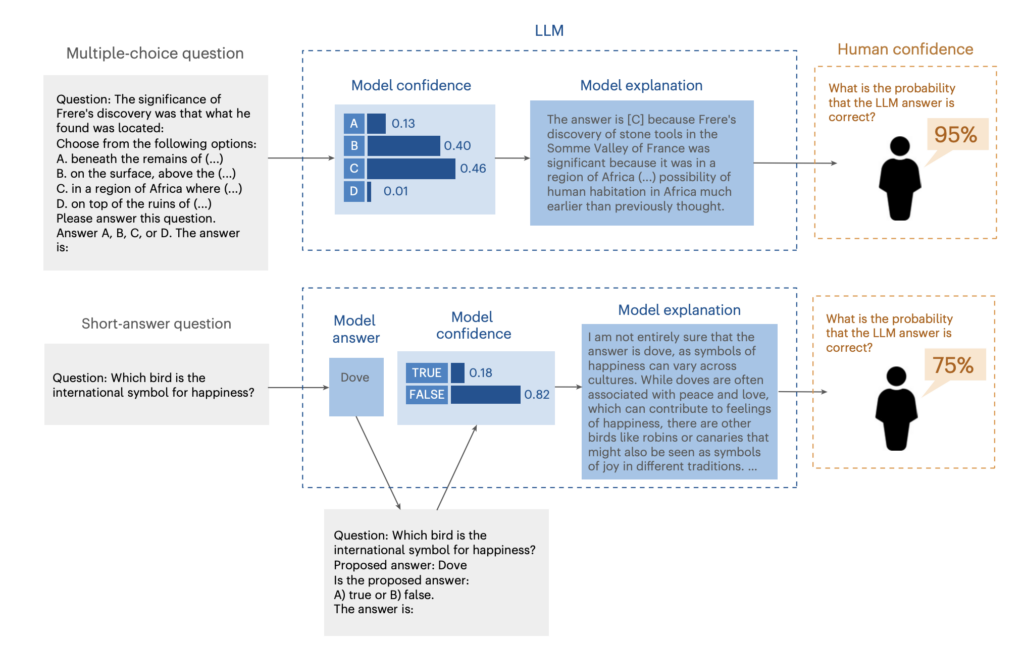
Zaufanie do systemów AI musi opierać się na ich zdolności do rzetelnej oceny i komunikowania własnej niepewności. Wyobraźmy sobie dwóch lekarzy. Jeden, mimo wewnętrznych wątpliwości, zawsze stawia diagnozę z absolutną pewnością. Drugi, gdy nie jest pewien, otwarcie to komunikuje, przedstawiając możliwe scenariusze. Któremu zaufamy bardziej w dłuższej perspektywie? Odpowiedź jest oczywista. Z AI jest podobnie, ale z jednym kluczowym problemem: nie mamy bezpośredniego wglądu w jego „wewnętrzne wątpliwości”.
Naukowcy zidentyfikowali i zmierzyli dwa kluczowe problemy w tej interakcji.
| Pojęcie | Definicja | W praktyce |
| Pewność siebie modelu (Model Confidence) | Wewnętrzna, numeryczna ocena prawdopodobieństwa, że wygenerowana odpowiedź jest poprawna. Użytkownik jej nie widzi. | Model może ocenić swoją odpowiedź na 46% szans poprawności. |
| Pewność siebie człowieka (Human Confidence) | Subiektywna ocena użytkownika, na ile procent odpowiedź modelu jest poprawna, oparta wyłącznie na przeczytanym tekście wyjaśnienia. | Użytkownik, czytając zgrabnie sformułowane wyjaśnienie, ocenia szansę poprawności na 95%. |
| Luka kalibracyjna (Calibration Gap) | Różnica między faktyczną pewnością siebie modelu a jej postrzeganiem przez człowieka. | W powyższym przykładzie luka jest ogromna (95% vs 46%). Użytkownik jest nadmiernie pewny poprawności odpowiedzi. |
| Luka dyskryminacyjna (Discrimination Gap) | Różnica w zdolności do odróżnienia odpowiedzi prawdopodobnie poprawnej od niepoprawnej między modelem a człowiekiem. | Model, dzięki swojej wewnętrznej ocenie, dobrze wie, kiedy jego odpowiedzi są ryzykowne. Człowiek, czytając standardowe wyjaśnienia, ma z tym duży problem. |
Eksperyment, który obnażył naszą naiwność
Aby zbadać te luki, naukowcy przeprowadzili serię eksperymentów behawioralnych z udziałem setek uczestników i trzech różnych modeli LLM (GPT-3.5, PaLM2, GPT-4o). Uczestnikom prezentowano odpowiedzi modeli na pytania wielokrotnego wyboru oraz pytania otwarte. Ich zadanie było proste: przeczytać wyjaśnienie i ocenić w skali procentowej, jak bardzo są pewni, że odpowiedź modelu jest prawidłowa.
Niepokojące wyniki: efekt nadmiernej pewności i pułapka długości
Wyniki pierwszej fazy badań, gdzie modele generowały standardowe, domyślne wyjaśnienia, okazały się alarmujące.
- Systematycznie przeceniamy AI. Uczestnicy byli konsekwentnie znacznie bardziej pewni poprawności odpowiedzi AI, niż wynikałoby to z wewnętrznej oceny samego modelu. Luka kalibracyjna jest faktem. Standardowy, asertywny ton odpowiedzi sprawia, że bezkrytycznie im ufamy.
- Dłuższe znaczy lepsze? To iluzja. Badanie ujawniło silną tendencję poznawczą: im dłuższe i bardziej szczegółowe było wyjaśnienie modelu, tym wyższa była ocena pewności siebie uczestników. Co kluczowe, ta dodatkowa długość tekstu w żaden sposób nie poprawiała faktycznej trafności odpowiedzi ani nie pomagała ludziom lepiej odróżnić prawdę od fałszu. Wpadamy w pułapkę, w której objętość tekstu mylimy z jego jakością i wiarygodnością.
- Jesteśmy słabi w wykrywaniu błędów. Podczas gdy wewnętrzne wskaźniki modeli AI pozwalały im z dużą skutecznością odróżniać odpowiedzi poprawne od błędnych, ludzie na podstawie samego tekstu radzili sobie z tym niewiele lepiej niż losowo. Luka dyskryminacyjna pokazuje, że domyślny styl komunikacji AI skutecznie maskuje sygnały o niskiej jakości odpowiedzi.
Proste rozwiązanie, które zmienia wszystko
Czy jesteśmy skazani na dezinformację ze strony nadmiernie elokwentnych maszyn? Druga faza eksperymentu przynosi nadzieję. Naukowcy zmodyfikowali sposób generowania odpowiedzi. Zamiast domyślnych wyjaśnień, zmusili modele, by rozpoczynały swoje odpowiedzi od fraz odzwierciedlających ich wewnętrzny poziom pewności, np.:
- Niska pewność: „Nie jestem pewien, czy odpowiedź to [X], ponieważ…”
- Średnia pewność: „Jestem dosyć pewien, że odpowiedź to [X], ponieważ…”
- Wysoka pewność: „Jestem pewien, że odpowiedź to [X], ponieważ…”
Efekt był natychmiastowy i znaczący. Kiedy język używany przez AI był bezpośrednio powiązany z jego wewnętrzną kalibracją:
- Luka kalibracyjna znacząco zmalała. Użytkownicy zaczęli znacznie lepiej oceniać realną szansę poprawności odpowiedzi.
- Luka dyskryminacyjna niemal zniknęła. Ludzie nauczyli się odróżniać odpowiedzi pewne od tych ryzykownych.
Odkrycia te pokazują, że problem nie leży w samej technologii, ale w sposobie jej projektowania. Obecne modele są często trenowane (poprzez proces RLHF – uczenie ze wzmocnieniem z ludzką informacją zwrotną), by generować odpowiedzi, które ludzie preferują – a ludzie, jak się okazuje, wolą odpowiedzi wyglądające na pewne i wyczerpujące.
Aby modele językowe stały się naprawdę godnymi zaufania partnerami w podejmowaniu decyzji, muszą nauczyć się nie tylko wiedzieć więcej, ale także komunikować swoją niewiedzę z „intelektualną pokorą”. Sposób, w jaki AI komunikuje, jest równie ważny jak to, co komunikuje.
FAQ – Najczęściej zadawane pytania
- Czy to oznacza, że mój chatbot celowo mnie oszukuje?
Nie, to nie jest celowe „oszustwo”. Model nie ma intencji. Jego zachowanie wynika z procesu treningowego, który nagradza generowanie odpowiedzi brzmiących przekonująco i wyczerpująco, ponieważ tacy byli ludzcy oceniający, którzy go „uczyli”. Skutkiem ubocznym jest nadmiernie asertywny ton, nawet przy niskiej pewności wewnętrznej. - Jak jako użytkownik mogę się chronić przed nadmiernym zaufaniem do AI?
Po pierwsze, zawsze podchodź do odpowiedzi AI krytycznie, zwłaszcza w ważnych sprawach. Po drugie, próbuj zadawać pytania sondujące, np. „Jakie są alternatywne punkty widzenia?” lub „Jakie są argumenty przeciwko tej odpowiedzi?”. Może to sprowokować model do ujawnienia niepewności. Po trzecie, weryfikuj kluczowe informacje w niezależnych, wiarygodnych źródłach. - Czy krótsza odpowiedź od AI jest zawsze bardziej godna zaufania?
Niekoniecznie. Badanie pokazuje, że długość sama w sobie jest mylącym wskaźnikiem. Zarówno krótka, jak i długa odpowiedź może być błędna. Kluczowym odkryciem jest to, że nie powinniśmy używać długości jako miary wiarygodności. Ważniejsza jest treść i, w przyszłości, jawnie komunikowany przez model poziom pewności. - Dlaczego modele AI nie robią tego standardowo?
Głównie z powodów komercyjnych i projektowych. Firmy chcą, aby ich produkty były postrzegane jako kompetentne i pomocne. Model, który ciągle mówi „nie wiem”, mógłby być oceniany jako mniej użyteczny. To badanie jest silnym argumentem za zmianą tego paradygmatu w kierunku większej transparentności. - Czy te luki dotyczą tylko odpowiedzi tekstowych?
Badanie skupiało się na tekście, ale problem kalibracji dotyczy wszystkich modalności AI, w tym generowania obrazów czy kodu. Zdolność systemu do oceny prawdopodobieństwa, że wygenerowana treść spełnia oczekiwania i jest poprawna, jest uniwersalnym wyzwaniem w dziedzinie sztucznej inteligencji.